Test data quality in an Airflow data pipeline
Last modified on 28-Oct-24
Use this guide as an example for how to set up and use Soda to test the quality of your data in an Airflow pipeline. Automatically catch data quality issues after ingestion or transformation to prevent negative downstream impact.
(Not quite ready for this big gulp of Soda? 🥤Try taking a sip, first.)
About this guide
Install Soda from the command-line
Connect Soda to a data source and Soda Cloud account
Write checks for data quality
Transform checks
Ingest checks
Reports checks
Create a DAG and run the workflow
Run Soda scans manually
View results and tag datasets
Go further
About this guide
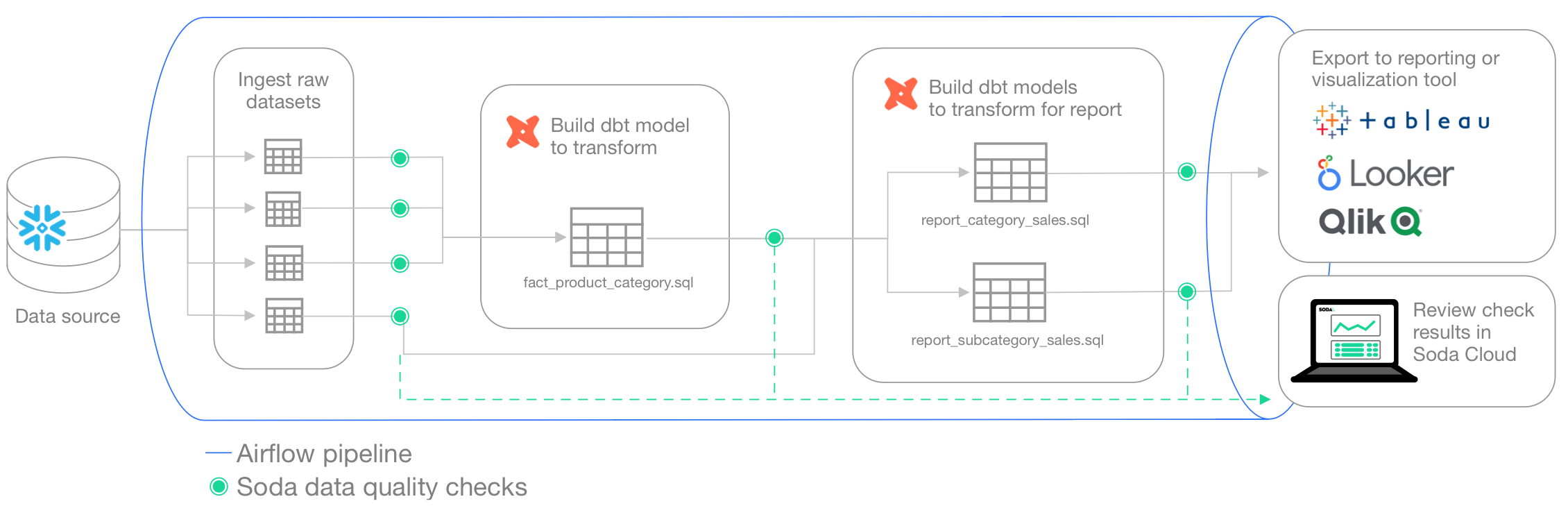
The instructions below offer Data Engineers an example of how to execute SodaCL checks for data quality on data in an Apache Airflow pipeline.
For context, this guide presents an example of a Data Engineer at a small firm who was tasked with building a simple products report of sales by category for AdventureWorks data. This Engineer uses dbt to build a simple model transformation to gather data, then builds more models to transform and push gathered information to a reporting and visualization tool. The Engineer uses Airflow for scheduling and monitoring workflows, including data ingestion and transformation events.
The Engineer’s goal in this example is to make sure that after such events, and before pushing information into a reporting tool, they run scans to check the quality of the data. Where the scan results indicate an issue with data quality, Soda notifies the Engineer so that they can potentially stop the pipeline and investigate and address any issues before the issue causes problems in the report.
Access the sodadata/sip-of-soda/test-data-in-pipeline folder to review the dbt models and Soda checks files that the Data Engineer uses.
Borrow from this guide to connect to your own data source, set up scan points in your pipeline, and execute your own relevant tests for data quality.
Install Soda from the command-line
With Python 3.8, 3.9, or 3.10 installed, the Engineer creates a virtual environment in Terminal, then installs the Soda package for PostgreSQL using the following command.
pip install -i https://pypi.cloud.soda.io soda-postgres
Refer to complete install instructions for all supported data sources, if you wish.
Connect Soda to a data source and Soda Cloud account
To connect to a data source such as Snowflake, PostgreSQL, Amazon Athena, or BigQuery, you use a configuration.yml file which stores access details for your data source.
This guide also includes instructions for how to connect to a Soda Cloud account using API keys that you create and add to the same configuration.yml file. Available for free as a 45-day trial, a Soda Cloud account gives you access to visualized scan results, tracks trends in data quality over time, enables you to set alert notifications, and much more.
- In the directory in which they work with their dbt models, the Data Engineer creates a
sodadirectory to contain the Soda configuration and check YAML files. - In the new directory, they create a new file called
configuration.yml. - In the
configuration.ymlfile, they add the data source connection configuration for the PostgreSQL data source that contains the AdventureWorks data. The example below is the connection configuration for a PostgreSQL data source. Access the example file. See a complete list of supported data sources.data_source soda-demo: type: postgres host: localhost username: postgres password: secret database: postgres schema: public - In a browser, they navigate to cloud.soda.io/signup to create a free, 45-day trial Soda account.
- They navigate to avatar > Profile, then navigate to the API Keys tab and click the plus icon to generate new API keys.
- They copy the syntax for the
soda_cloudconfiguration, including the values API Key ID and API Key Secret, and paste it into theconfiguration.yml. - They are careful not to nest the
soda_cloudconfiguration in thedata_sourceconfiguration.
- They copy the syntax for the
- They save the
configuration.ymlfile and close the API modal in the Soda account. - In Terminal, they run the following command to test Soda’s connection to the data source.
soda test-connection -d adventureworks -c configuration.yml
Write checks for data quality
A check is a test that Soda executes when it scans a dataset in your data source. The checks.yml file stores the checks you write using the Soda Checks Language (SodaCL). You can create multiple checks.yml files to organize your data quality checks and run all, or some of them, at scan time.
In this example, the Data Engineer creates multiple checks after ingestion, after initial transformation, and before pushing the information to a visualization or reporting tool.
Transform checks
After building a simple dbt model transformation that creates a new fact table which gathers data about products, product categories, and subcategories (see dbt model), the Engineer realizes that some of the products in the dataset do not have an assigned category or subcategory, which means those values would erroneously be excluded from the report.
To mitigate the issue and get a warning when these values are missing, they create a new checks YAML file and write the following checks to execute after the transformation produces the fact_product_category dataset.
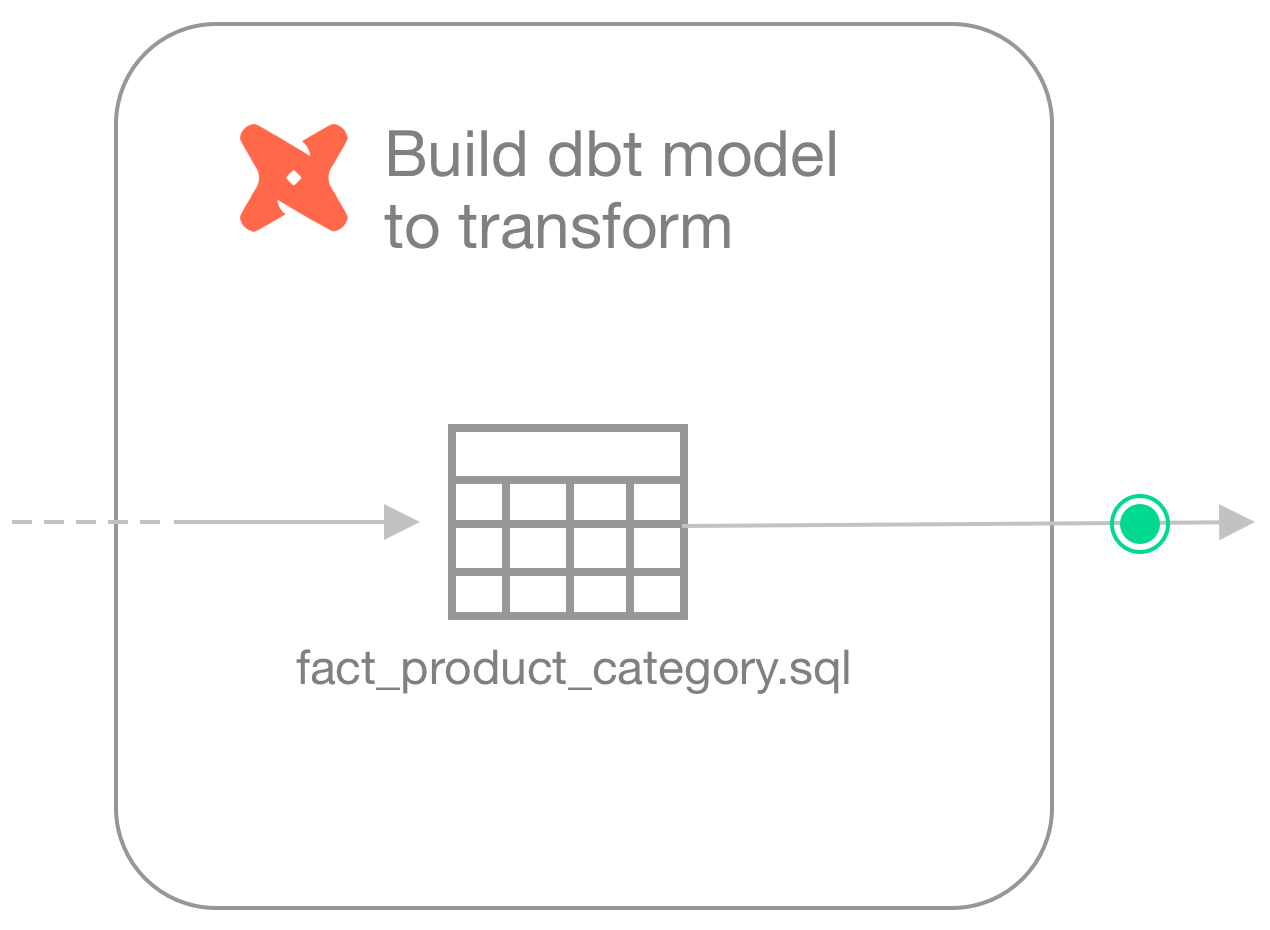
checks for fact_product_category:
# Check warns when any NULL values exist in the column
- missing_count(category_key):
name: All products have a category
warn: when > 0
# Check warns when any NULL values exist in the column
- missing_count(subcategory_key):
name: All products have a subcategory
warn: when > 0
# Check warns when any NULL values exist in the column
- missing_count(product_key) = 0:
name: All products have a key
Ingest checks
Because the Engineer does not have the ability or access to fix upstream data themselves, they create another checks YAML file write checks to apply to each dataset they use in the transformation, after the data is ingested, but before it is transformed.
For any checks that fail, the Engineer can notify upstream Data Engineers or Data Product Owners to address the issue of missing categories and subcategories.
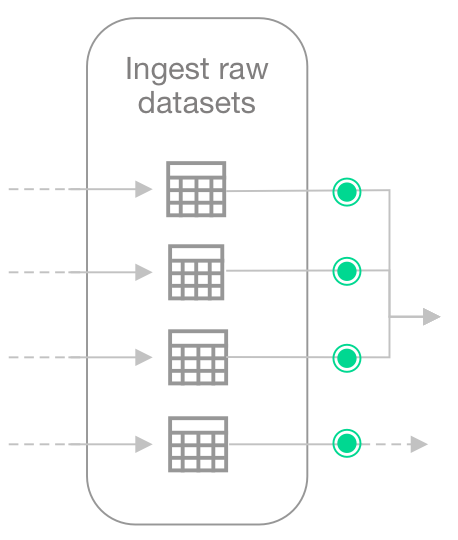
checks for dim_product:
# Check fails when product_key or english_product_name is missing, OR
# when the data type of those columns is other than specified
- schema:
fail:
when required column missing: [product_key, english_product_name]
when wrong column type:
product_key: integer
english_product_name: varchar
# Check fails when any NULL values exist in the column
- missing_count(product_key) = 0:
name: All products have a key
# Check fails when any NULL values exist in the column
- missing_count(english_product_name) = 0:
name: All products have a name
# Check fails when any NULL values exist in the column
- missing_count(product_subcategory_key):
name: All products have a subcategory
warn: when > 0
# Check fails when the number of products, relative to the
# previous scan, changes by 10 or more
- change for row_count < 10:
name: Products are stable
checks for dim_product_category:
# Check fails when product_category_key or english_product_category name
# is missing, OR
# when the data type of those columns is other than specified
- schema:
fail:
when required column missing:
[product_category_key, english_product_category_name]
when wrong column type:
product_category_key: integer
english_product_category_name: varchar
# Check fails when any NULL values exist in the column
- missing_count(product_category_key) = 0:
name: All categories have a key
# Check fails when any NULL values exist in the column
- missing_count(english_product_category_name) = 0:
name: All categories have a name
# Check fails when the number of categories, relative to the
# previous scan, changes by 5 or more
- change for row_count < 5:
name: Categories are stable
checks for dim_product_subcategory:
# Check fails when product_subcategory_key or english_product_subcategory_name
# is missing, OR
# when the data type of those columns is other than specified
- schema:
fail:
when required column missing:
[product_subcategory_key, english_product_subcategory_name]
when wrong column type:
product_subcategory_key: integer
english_product_subcategory_name: varchar
# Check fails when any NULL values exist in the column
- missing_count(product_subcategory_key) = 0:
name: All subcategories have a key
# Check fails when any NULL values exist in the column
- missing_count(english_product_subcategory_name) = 0:
name: All subcategories have a name
# Check fails when the number of categories, relative to the
# previous scan, changes by 5 or more
- change for row_count < 5:
name: Subcategories are stable
checks for fact_internet_sales:
# Check fails when product_key, order_quantity, or sales_amount
# is missing, OR
# when the data type of those columns is other than specified
- schema:
fail:
when required column missing:
[product_key, order_quantity, sales_amount]
when wrong column type:
product_key: integer
order_quantity: smallint
sales_amount: money
# Check fails when any NULL values exist in the column
- missing_count(product_key) = 0:
name: All sales have a product associated
# Check fails when any order contains no items
- min(order_quantity) > 0:
name: All sales have a non-zero order quantity
# Check fails when the amount of any sales order is zero
- failed rows:
name: All sales have a non-zero order amount
fail query: |
SELECT sales_order_number, sales_amount::NUMERIC
FROM fact_internet_sales
WHERE sales_amount::NUMERIC <= 0
# Check warns when there are fewer than 5 new internet sales
# relative to the previous scan resuls
# Check fails when there are more than 500 new internet sales
# relative to the previous scan resuls
- change for row_count:
warn: when < 5
fail: when > 500
name: Sales are within expected range
# Check fails when the average of the column is abnormal
# relative to previous measurements for average sales amount
# sales_amount is cast from data type MONEY to enable calculation
- anomaly detection for avg(sales_amount::NUMERIC)
Reports checks
Finally, the Engineer builds category and subcategory sales report models sales report models using dbt.
The checks files they create to run on the new transform models contain similiar user-defined checks. Ultimately, the Engineer wants data quality checks to fail if the sales of uncategorized products rises above normal (0.85%), and if the sum of sales orders in the model that prepares the report differs greatly from the sum of raw sales order number.
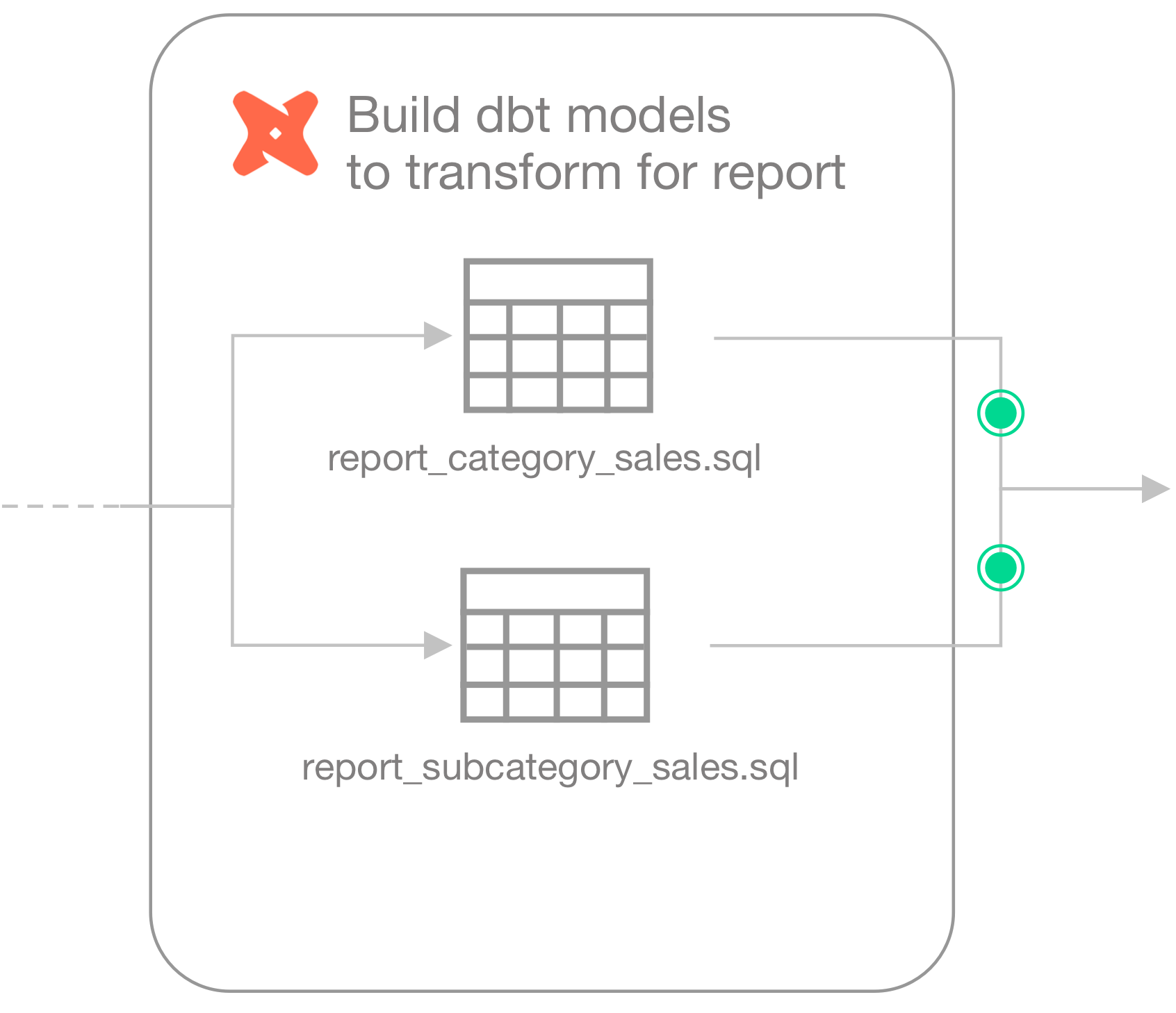
checks for report_category_sales:
# Check fails if the percentage of sales of products with no
# catgory exceeds 0.90%
- uncategorized_sales_percent < 0.9:
uncategorized_sales_percent query: >
select ROUND(CAST((sales_total * 100) / (select sum(sales_total) from report_category_sales) AS numeric), 2) as uncategorized_sales_percent from report_category_sales where category_key is NULL
name: Most sales are categorized
# Check fails if the sum of sales produced by the model is different
# than the sum of sales in the fact_internet_sales dataset
- sales_diff = 0:
name: Category sales total matches
sales_diff query: >
SELECT CAST((SELECT SUM(fact_internet_sales.sales_amount) FROM fact_internet_sales)
- (SELECT SUM(report_category_sales.sales_total) FROM report_category_sales) as numeric) AS sales_diff
checks for report_subcategory_sales:
# Check fails if the percentage of sales of products with no
# subcategory exceeds 0.90%
- uncategorized_sales_percent < 0.9:
uncategorized_sales_percent query: >
select ROUND(CAST((sales_total * 100) / (select sum(sales_total) from report_subcategory_sales) AS numeric), 2) as uncategorized_sales_percent from report_subcategory_sales where category_key is NULL OR subcategory_key is NULL
name: Most sales are categorized
# Check fails if the sum of sales produced by the model is different
# than the sum of sales in the fact_internet_sales dataset
- sales_diff = 0:
name: Subcategory sales total matches
sales_diff query: >
SELECT CAST((SELECT SUM(fact_internet_sales.sales_amount) FROM fact_internet_sales)
- (SELECT SUM(report_subcategory_sales.sales_total) FROM report_subcategory_sales) as numeric) AS sales_diff
Create a DAG and run the workflow
The Engineer creates an Airflow DAG and runs the workflow locally. Note that the value for scan-name must be unique to every programmatic scan you define. In other words, it cannot be the same as a programmatic scan in another pipeline.
Access the DAG in the repo.
from airflow import DAG
from airflow.models.variable import Variable
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonVirtualenvOperator
from airflow.operators.dummy import DummyOperator
from airflow.utils.dates import days_ago
from datetime import timedelta
default_args = {
"owner": "soda",
"retries": 1,
"retry_delay": timedelta(minutes=5),
}
PROJECT_ROOT = "<this_project_full_path_root>"
def run_soda_scan(project_root, scan_name, checks_subpath = None):
from soda.scan import Scan
print("Running Soda Scan ...")
config_file = f"{project_root}/soda/configuration.yml"
checks_path = f"{project_root}/soda/checks"
if checks_subpath:
checks_path += f"/{checks_subpath}"
data_source = "soda_demo"
scan = Scan()
scan.set_verbose()
scan.add_configuration_yaml_file(config_file)
scan.set_data_source_name(data_source)
scan.add_sodacl_yaml_files(checks_path)
scan.set_scan_definition_name(scan_name)
result = scan.execute()
print(scan.get_logs_text())
if result != 0:
raise ValueError('Soda Scan failed')
return result
with DAG(
"model_adventureworks_sales_category",
default_args=default_args,
description="A simple Soda Library scan DAG",
schedule_interval=timedelta(days=1),
start_date=days_ago(1),
):
ingest_raw_data = DummyOperator(task_id="ingest_raw_data")
checks_ingest = PythonVirtualenvOperator(
task_id="checks_ingest",
python_callable=run_soda_scan,
requirements=[ "-i https://pypi.cloud.soda.io", "soda-postgres", "soda-scientific"],
system_site_packages=False,
op_kwargs={
"project_root": PROJECT_ROOT,
"scan_name": "model_adventureworks_sales_category_ingest",
"checks_subpath": "ingest/dim_product_category.yml"
},
)
dbt_transform = BashOperator(
task_id="dbt_transform",
bash_command=f"dbt run --project-dir {PROJECT_ROOT}/dbt --select transform",
)
checks_transform = PythonVirtualenvOperator(
task_id="checks_transform",
python_callable=run_soda_scan,
requirements=["-i https://pypi.cloud.soda.io", "soda-postgres", "soda-scientific"],
system_site_packages=False,
op_kwargs={
"project_root": PROJECT_ROOT,
"scan_name": "model_adventureworks_sales_category_transform",
"checks_subpath": "transform"
},
)
dbt_report = BashOperator(
task_id="dbt_report",
bash_command=f"dbt run --project-dir {PROJECT_ROOT}/dbt --select report",
)
checks_report = PythonVirtualenvOperator(
task_id="checks_report",
python_callable=run_soda_scan,
requirements=["-i https://pypi.cloud.soda.io", "soda-postgres", "soda-scientific"],
system_site_packages=False,
op_kwargs={
"project_root": PROJECT_ROOT,
"scan_name": "model_adventureworks_sales_category_report",
"checks_subpath": "report"
},
)
publish_data = DummyOperator(task_id="publish_data")
ingest_raw_data >> checks_ingest >> dbt_transform >> checks_transform >> dbt_report >> checks_report >> publish_data
Run Soda scans manually
Without using an Airflow DAG, the Engineer can use Soda locally to run scans for data quality using the checks YAML files they created.
- They use the
soda scancommand to run the ingest checks on the raw data, pointing Soda to the checks YAML files in theingest-checksfolder.soda scan -d soda_demo -c soda/configuration.yml soda/ingest-checks/ - If the ingest check results pass, they run dbt to create the new
fact_product_categorydataset.dbt run --project-dir dbt --select transform - Accordingly, they run a scan on the new dataset, pointing Soda to the checks YAML file in the
transform-checksfolder.soda scan -d soda_demo -c soda/configuration.yml soda/transform-checks/ - If the transform check results pass, they run dbt to create the reports.
dbt run --project-dir dbt --select report - Lastely, they run a scan on the reports data, pointing Soda to the checks YAML file in the
reports-checksfolder.soda scan -d soda_demo -c soda/configuration.yml soda/resports-checks/ - If the reports check results pass, the data is reliable enough to push to the reporting or visualization tool for consumers.
Learn more about running Soda scans.
View results and tag datasets
- In their Soda Cloud account, the Engineer clicks Checks to access the Checks dashboard. The checks from the scan that Soda performed during the scan appear in the table where they can click each line item to learn more about the results, as in the example below.
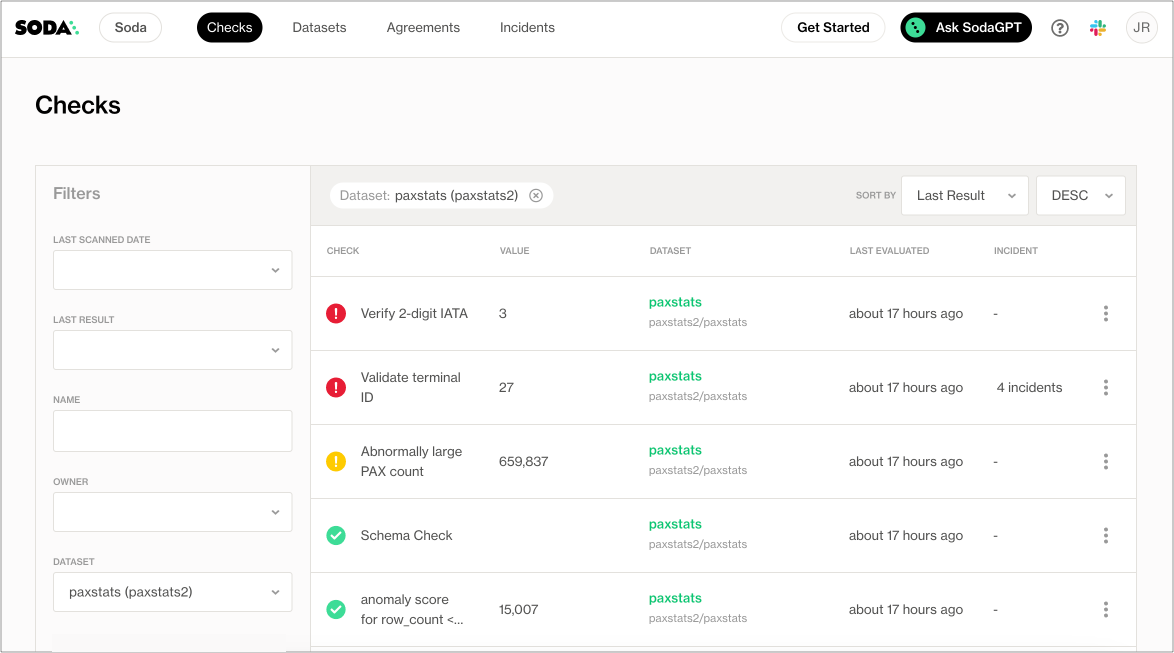
- To more easily retrieve Soda scan results by dbt model, the Engineer navigates to Datasets, then clicks the stacked dots at the right of the
dim_productdataset and selects Edit Dataset. - In the Tags field, they add a value for
fact_product_category, the dbt model that uses this dataset, and a tag to indicate the kind of data that Soda is scanning,raw,transformedorreporting, then saves. They repeat these steps to add tags to all the datasets in their Soda Cloud account. - Navigating again to the Datasets page, they use the filters to display datasets according to Tags and Arrival Time to narrow the search for the most recent quality checks associated with their models which have failed or warned.
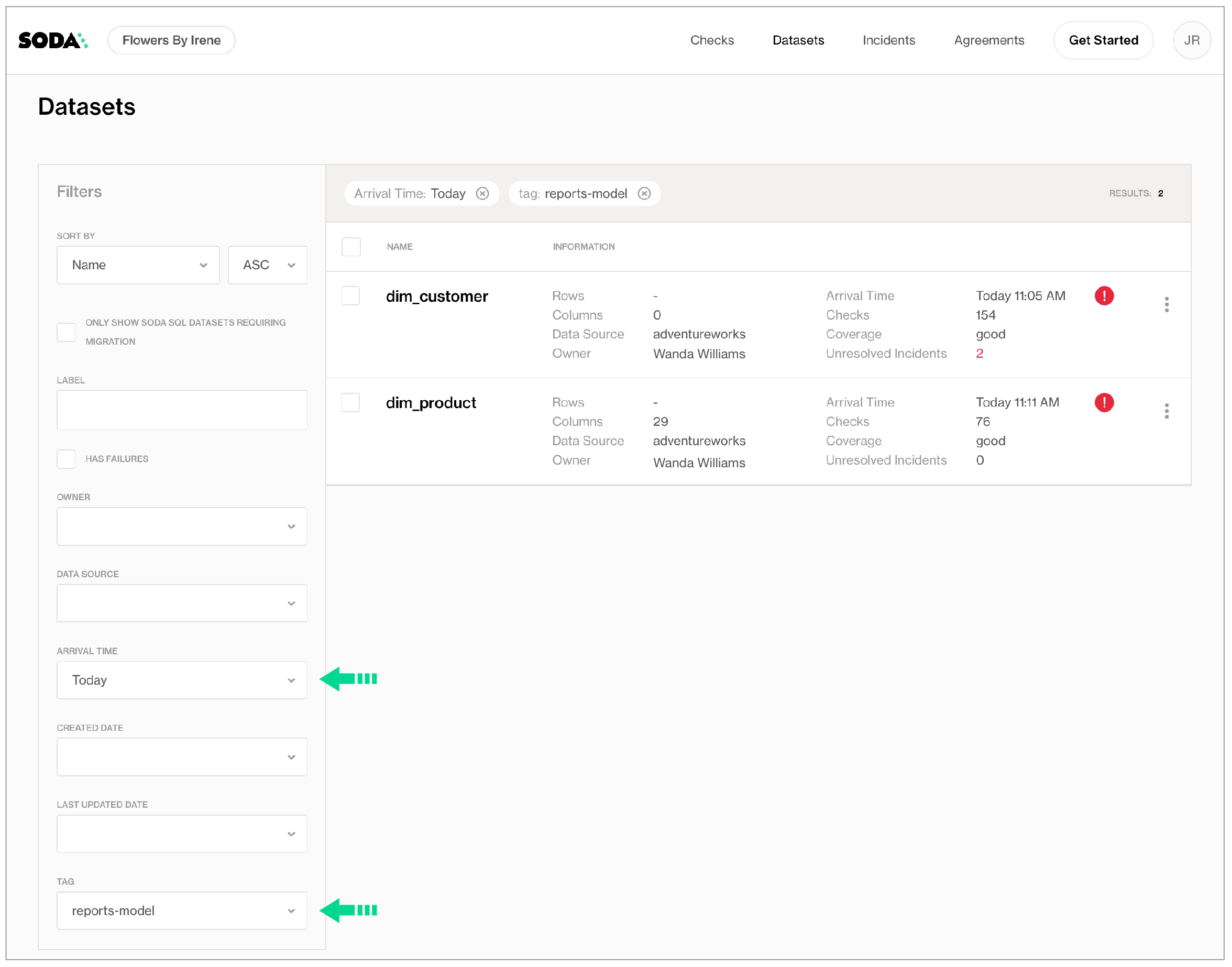
- After filtering the datasets according to the tags, the Engineer saves the filter setup as a Collection that they can revisit daily.
- If you were in the Data Engineer’s shoes, you may further wish to set up Slack notifications for any checks that warn or fail during scans.
✨Hey, hey!✨ Now you know what it’s like to add data quality checks to your production data pipeline. Huzzah!
Go further
- Get organized in Soda!
- Request a demo. Hey, what can Soda do for you?
- Join the Soda community on Slack.
Was this documentation helpful?
What could we do to improve this page?
- Suggest a docs change in GitHub.
- Share feedback in the Soda community on Slack.
Documentation always applies to the latest version of Soda products
Last modified on 28-Oct-24