Build a customized dashboard
Last modified on 21-Oct-24
This guide offers a comprehensive example for building a customized data quality reporting dashboard in Sigma. Use the Soda Cloud API to capture metadata from your Soda Cloud account, store it in Snowflake, then access the data in Snowflake to create a Sigma dashboard.

Prerequisites
Set up a Python script
Capture and store metadata
Build a data quality dashboard in Sigma
Go further
Prerequisites
- Python 3.8, 3.9, or 3.10
- Pip 21.0 or greater
- access to an account in Sigma
- access to a Snowflake data source
- a Soda Cloud account; see Get started
- permission in Soda Cloud to access dataset metadata; see Manage dataset roles
Set up a Python script
- Install an HTTP request library and Snowflake connector.
pip install pandas requests pip install snowflake-connector-python - In a new Python script, configure the following details to integrate with Soda Cloud. See Generate API keys for detailed instructions.
# Use cloud.us.soda.io in the US region; use cloud.soda.io in the EU region soda_cloud_url = 'https://cloud.us.soda.io' soda_apikey = 'xxx' # API key ID from Soda Cloud soda_apikey_secret = 'xxx' # API key secret from Soda Cloud - In the same script, define the tables in which to store the Soda dataset information and check results in Snowflake, ensuring they are in uppercase to avoid issues with Snowflake’s case sensitivity requirements.
# Tables to store Soda metadata. Use UPPERCASE. datasets_table = 'DATASETS_REPORT' checks_table = 'CHECKS_REPORT' - In the same script, configure your Snowflake connection details. This configuration enables your script to securely access your Snowflake data source.
# Snowflake connection details snowflake_details = snowflake.connector.connect( user=user, password=password, account=account, warehouse=warehouse, database=database, schema=schema, ) - In the script, prepare an HTTP
GETrequest to the Soda Cloud API to retrieve dataset information. Direct the request to the Dataset information endpoint, including the authentication API keys to access the data. This script prints an error if the request is unauthorized.response_datasets = requests.get( soda_cloud_url + '/api/v1/datasets?page=0', auth=(soda_apikey , soda_apikey_secret) ) if response_datasets.status_code == 401 or response_datasets.status_code == 403: print("Unauthorized or Forbidden access. Please check your API keys and/or permissions in Soda.") sys.exit() - Run the script to ensure that the
GETrequest results in HTTP status code200, confirming the successful connection to Soda Cloud.
Capture and store metadata
- With a functional connection to Soda Cloud, adjust the API call to extract all dataset information from Soda Cloud, iterating over each page of the datasets. Then, create a Pandas Dataframe to contain the retrieved metadata.
This adjusted call retrieves information about each dataset’s name, its last update, the data source in which it exists, its health status, and the volume of checks and incidents with which it is associated.# Fetch info about all datasets if response_datasets.status_code == 200: dataset_pages = response_datasets.json().get('totalPages') i = 0 while i < dataset_pages: dq_datasets = requests.get( soda_cloud_url + '/api/v1/datasets?page='+str(i), auth=(soda_apikey , soda_apikey_secret)) if dq_datasets.status_code == 200: print("Fetching all datasets on page: "+str(i)) list = dq_datasets.json().get("content") datasets.extend(list) i += 1 elif dq_datasets.status_code == 429: print("API Rate Limit reached when fetching datasets on page: " +str(i)+ ". Pausing for 30 seconds.") time.sleep(30) # Retry fetching the same page else: print("Error fetching datasets on page "+str(i)+". Status code:", dq_datasets.status_code) else: print("Error fetching initial datasets. Status code:", response_datasets.status_code) sys(exit) df_datasets = pd.DataFrame(datasets) - Inspect the information you retrieved with the following Pandas command; see example output below.
df_datasets.head()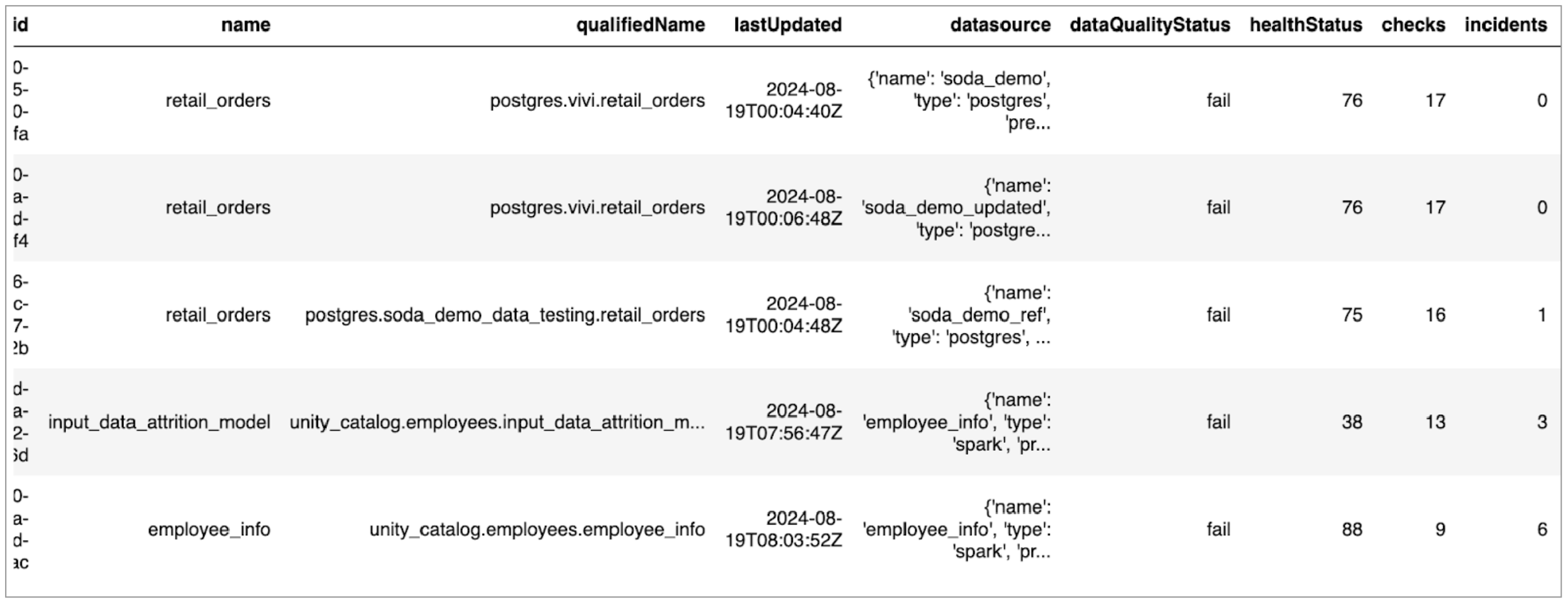
- Following the same logic, extract all the check-related information from Soda Cloud using the Checks information endpoint.
This call retrieves information about the checks in Soda Cloud, including the dataset and column each runs against, the latest check evaluation time and the result – pass, warn, or fail – and any attributes associated with the check.# Fetch info about all checks response_checks = requests.get( soda_cloud_url + '/api/v1/checks?size=100', auth=(soda_apikey , soda_apikey_secret)) if response_checks.status_code == 200: check_pages = response_checks.json().get('totalPages') i = 0 while i < check_pages: dq_checks = requests.get( soda_cloud_url + '/api/v1/checks?size=100&page='+str(i), auth=(soda_apikey , soda_apikey_secret)) if dq_checks.status_code == 200: print("Fetching all checks on page "+str(i)) check_list = dq_checks.json().get("content") checks.extend(check_list) i += 1 elif dq_checks.status_code == 429: print("API Rate Limit reached when fetching checks on page: " +str(i)+ ". Pausing for 30 seconds.") time.sleep(30) # Retry fetching the same page else: print("Error fetching checks on page "+str(i)+". Status code:", dq_checks.status_code) else: print("Error fetching initial checks. Status code:", response_checks.status_code) sys(exit) df_checks = pd.DataFrame(checks) - Again, inspect the output with a Pandas command.
df_checks.head()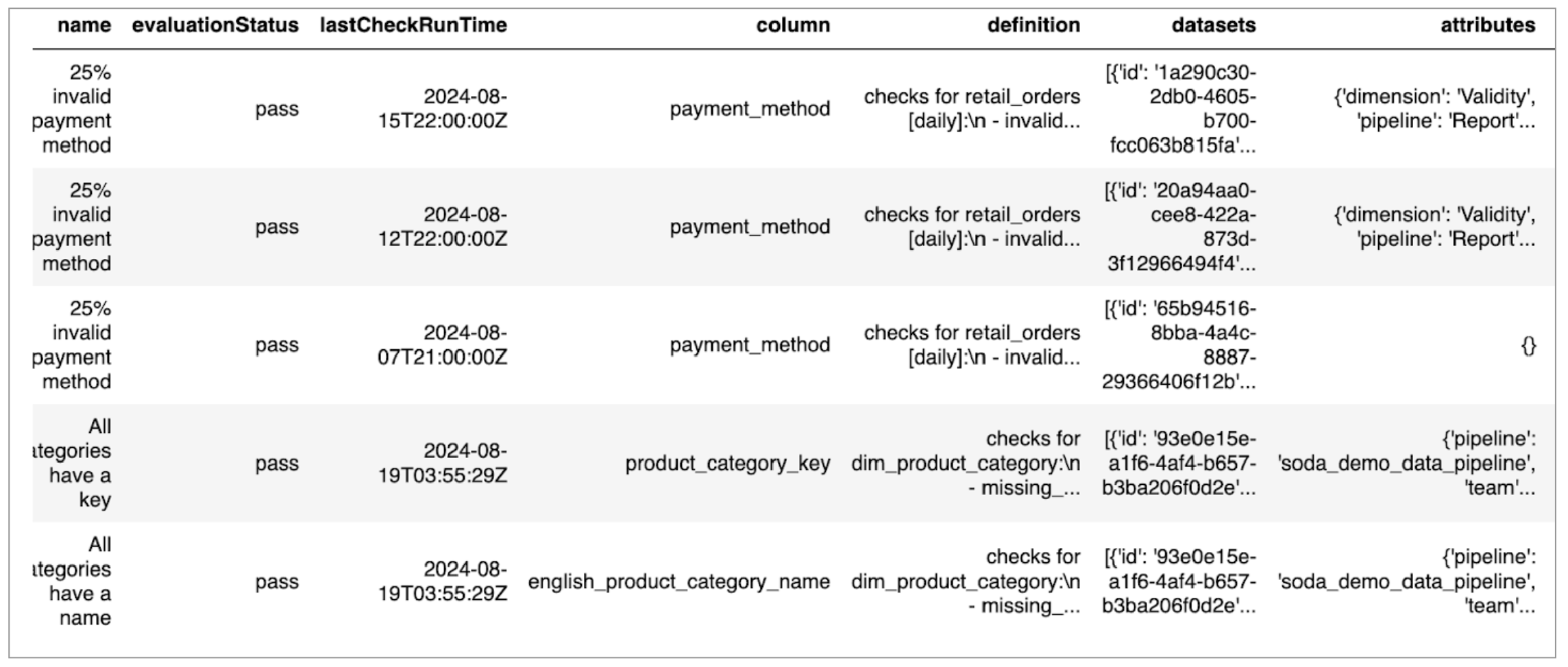
- Finally, move the two sets of metadata into your Snowflake data source. Optionally, if you wish to track updates and changes to dataset and check metadata over time, you can store the metadata to incremental tables and set up a flow to update the values on a regular basis using the latest information retrieved from Soda Cloud.
write_pandas(snowflake_details, df_checks, checks_table, auto_create_table=True) write_pandas(snowflake_details, df_datasets, datasets_table, auto_create_table=True) - Run the script to populate the tables in Snowflake with the metadata pulled from Soda Cloud.
Build a data quality dashboard in Sigma
To build a custom dashboard, this example uses Sigma, a cloud-based analytics and business intelligence platform designed to facilitate data exploration and analysis. You may wish to use a different tool to build a dashboard such as Metabase, Lightdash, Looker, PowerBI, or Tableau.
This example leverages check attributes, an optional configuration that helps categorize or segment check results so you can better filter and organize not only your views in Soda Cloud, but your customized dashboard. Checks in this example use the following attributes:
- Data Quality Dimension: Completeness, Validity, Consistency, Accuracy, Timeliness, Uniqueness
- Data Domain: Customer, Location, Product, Transaction
- Data Team: Data Engineering, Data Science, Sales Operations
- Pipeline stage: Destination, Ingest, Report, Transform
- Weight
The weight attribute, in particular, is very useful in allocating a numerical level of importance to checks which you can use to create a custom data health quality score.
- Follow the Sigma documentation to Connect to Snowflake.
- Follow Sigma documentation to access the metadata you stored in Snowflake, either by Modeling data from database tables, or Creating a dataset by writing custom SQL.
- Create a new workbook in Sigma where you can create your visualizations.
The Sigma dashboard below tracks data quality status within an organization. It includes some basic KPI information including the number of datasets monitored by Soda, as well as the number of checks that it regularly executes. It displays a weighted data quality score based on the custom values provided in the Weight attribute for each check (here shown according to data quality dimension) which it compares to previous measurements gathered over time.
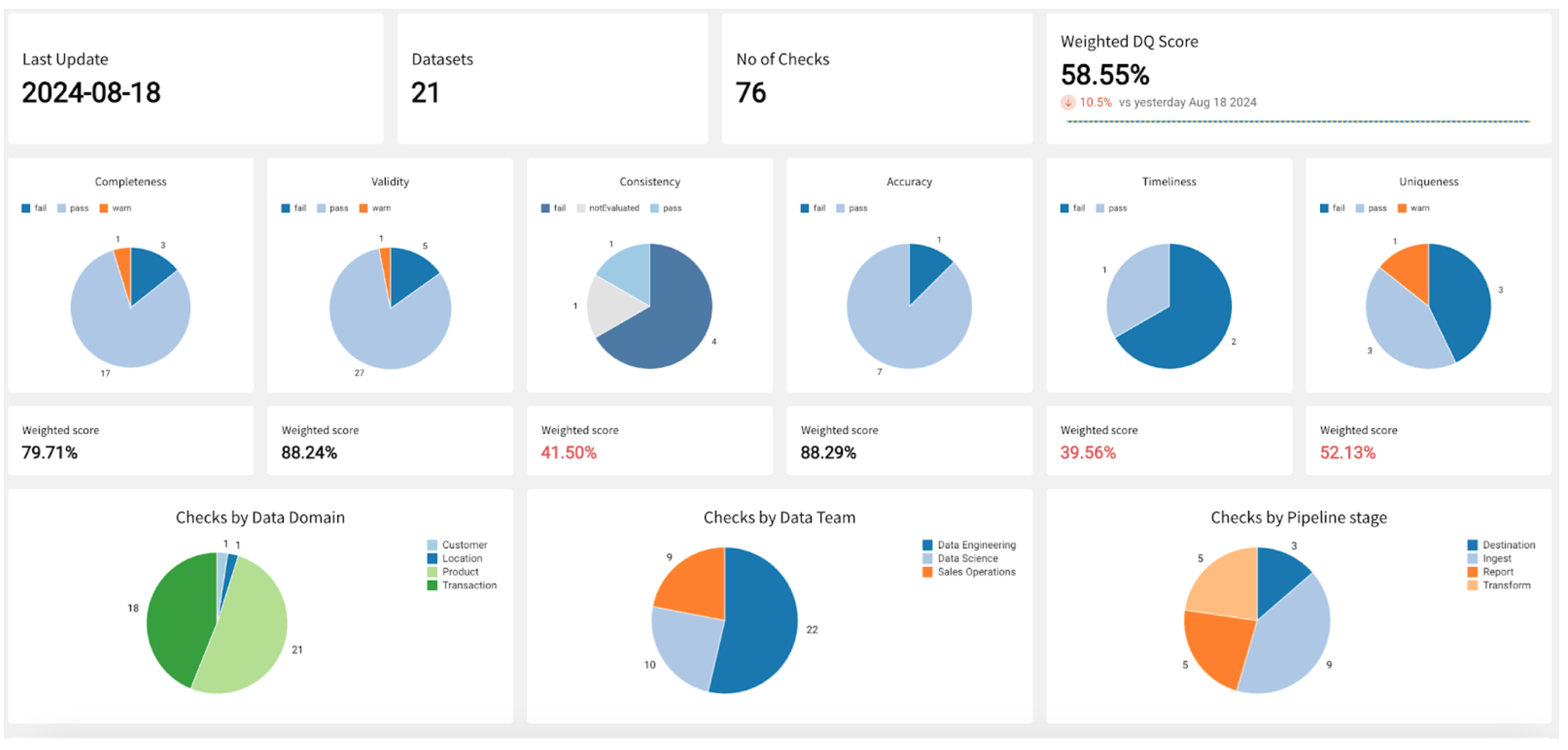
Go further
- Access full Soda Cloud API and Soda Cloud Reporting API documentation.
- Learn more about check attributes and dataset attributes.
- Need help? Join the Soda community on Slack.
Was this documentation helpful?
What could we do to improve this page?
- Suggest a docs change in GitHub.
- Share feedback in the Soda community on Slack.
Documentation always applies to the latest version of Soda products
Last modified on 21-Oct-24