Test data quality before migration
Last modified on 08-Aug-24
Use this guide to install and set up Soda to test the quality in a data migration project. Test data quality at both source and target, both before and after migration to prevent data quality issues from polluting a new data source.
(Not quite ready for this big gulp of Soda? 🥤Try taking a sip, first.)
About this guide
Prepare for data migration
Install and set up Soda
Migrate data in staging
Reconcile data and migrate in production
Go further
About this guide
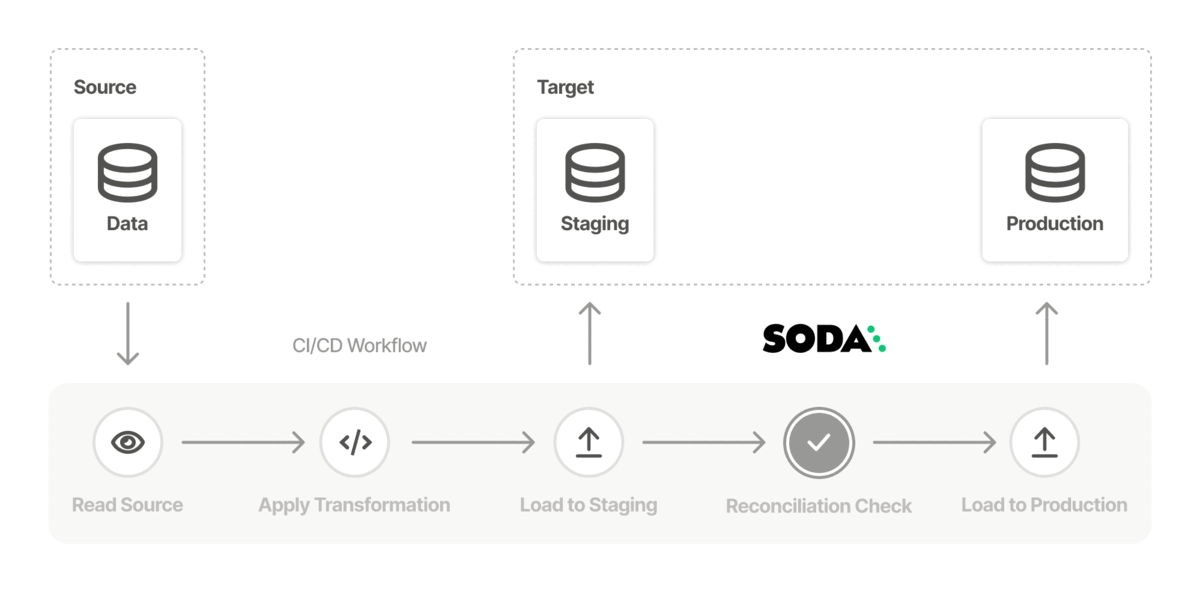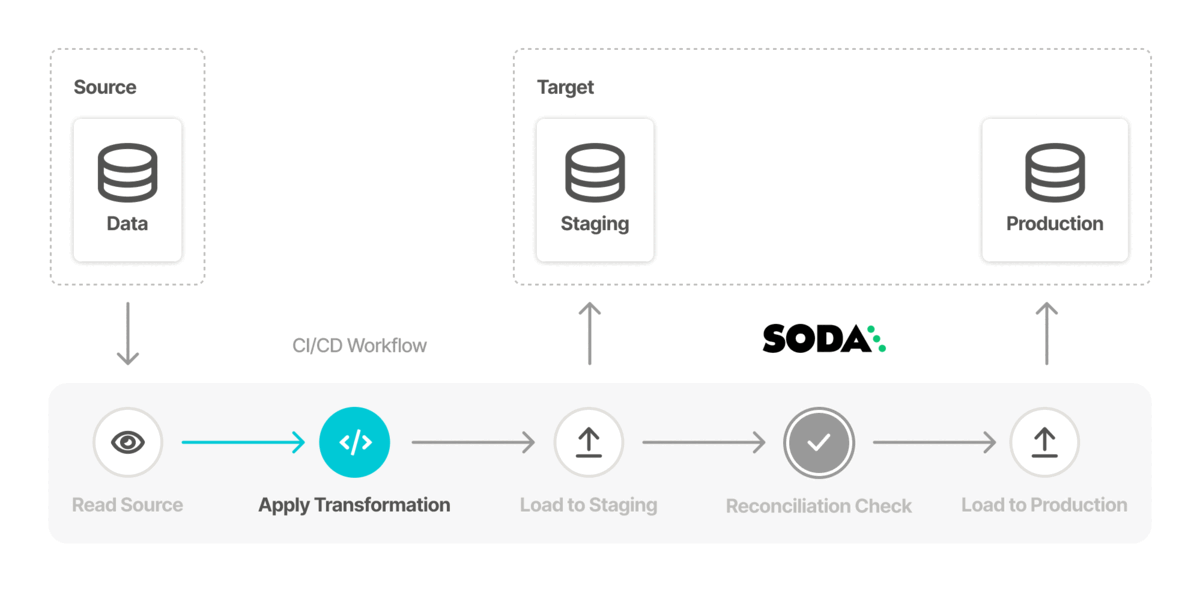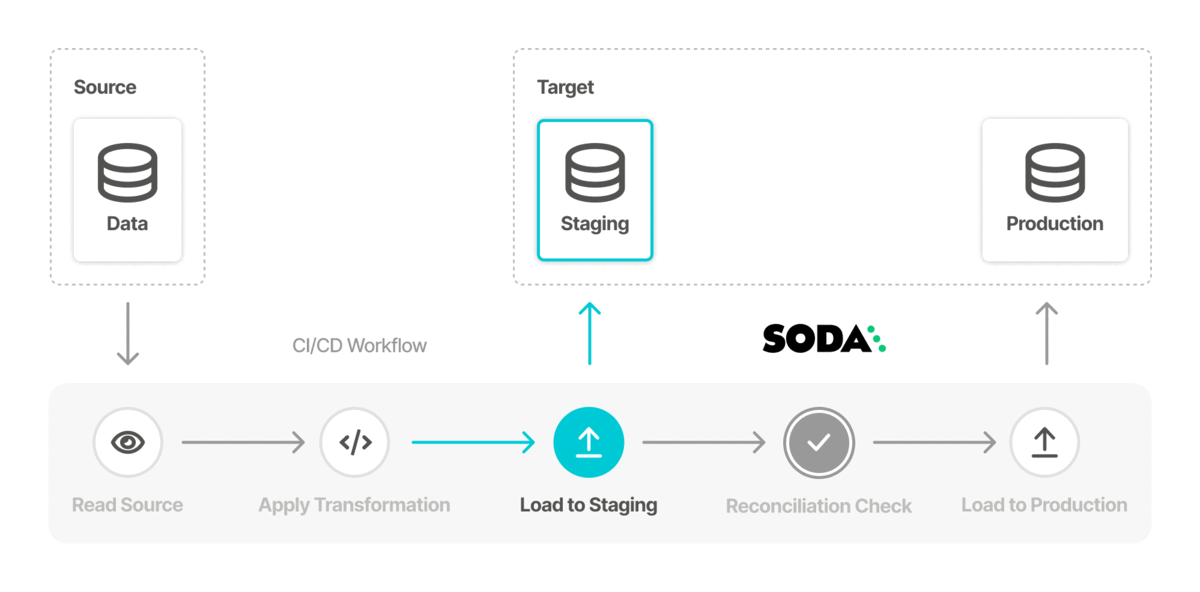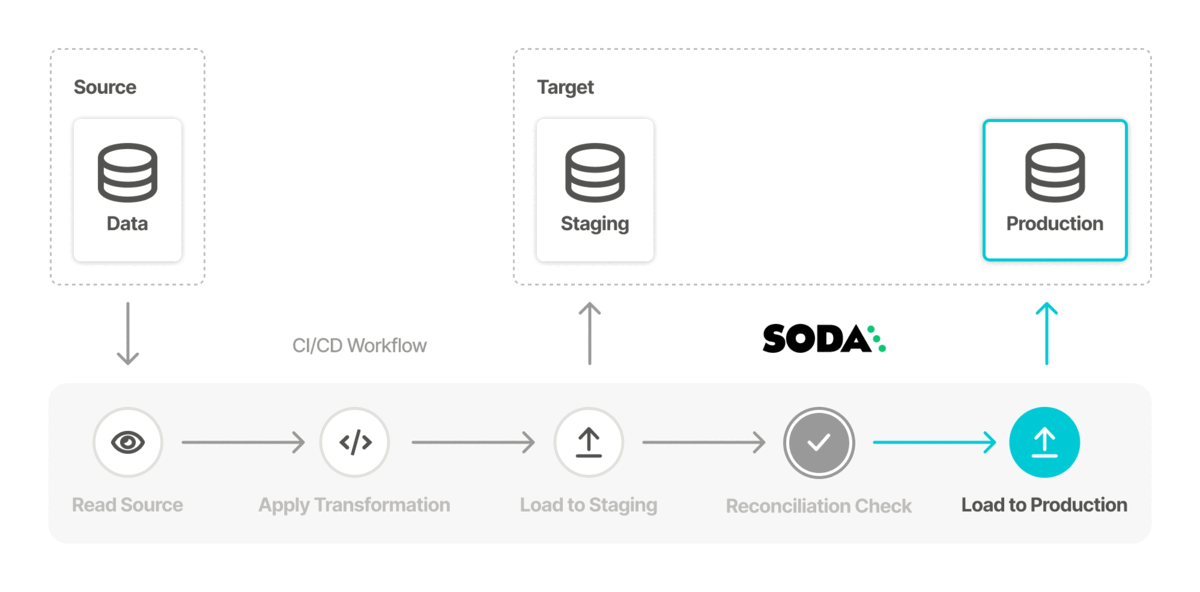
The instructions below offer Data Engineers an example of how to set up Soda and use reconciliation checks to compare data quality between data sources before and after migrating data.
For context, this guide presents an example of how you could use Soda to prepare to migrate data from one data source, such as PostgreSQL to another, such as Snowflake. It makes suggestions about how to prepare for a data migration project and use a staging environment to validate data quality before migrating data in production.
This example uses a self-operated deployment model which uses Soda Library and Soda Cloud, though you could as easily use a self-hosted agent model (Soda Agent and Soda Cloud) instead.
Prepare for data migration
This example imagines moving data from PostgreSQL to Snowflake. The following outlines the high level steps involved in preparing for and executing such a project.
- Confirm your access to the source data in a PostgreSQL data source; you have the authorization and access credentials to query the data.
- Set up or confirm that you have a Snowflake account and the authorization and credentials to set up and query a new data source.
- Confirm that you have a data orchestration tool such as Airflow to extract data from PostgreSQL, perform any transformations, then load the data into Snowflake. Reference Migrating data using Airflow for an Airflow setup example.
- Install and set up Soda to perform preliminary tests for data quality in the source data. Use this opportunity to make sure that the quality of the data you are about to migrate is in a good state. Ideally, you perform this step in a production environment, before replicating the source data source in a staging environment to ensure that you begin the project with good-quality data.
- You have backed up the existing data in the PostgreSQL source data source, and created a staging environment which replicates the production PostgreSQL data source.
- Use Airflow to execute the data migration from PostgreSQL to Snowflake in a staging environment.
- In the staging environment, use Soda to run reconciliation checks on both the source and target data sources to validate that the data has been transformed and loaded as expected, and the quality of data in the target is sound.
- Adjust your data transformations as needed in order to address any issues surfaced by Soda. Repeat the data migration in staging, checking for quality after each run, until you are satisfied with the outcome and the data that loads into the target Snowflake data source.
- Prepare an Airflow DAG to execute the data migration in production. Execute the data migration in production, then use Soda to scan for data quality on the target data source for final validation.
- (Optional) For regular migration events, consider invoking Soda scans for data quality after extraction and transformation(s) in the DAG.
Install and set up Soda
What follows is an abridged version of installing and configuring Soda for PostgreSQL. Refer to full installation instructions for details.
- In a browser, navigate to cloud.soda.io/signup to create a new Soda account, which is free for a 45-day trial. If you already have a Soda account, log in.
- Navigate to your avatar > Profile, then access the API keys tab. Click the plus icon to generate new API keys. Copy+paste the API key values to a temporary, secure place in your local environment.
- With Python 3.8, 3.9, or 3.10 and Pip 21.0 or greater, use the command-line to install Soda locally in a new virtual environment.
python3 -m venv .venv source .venv/bin/activate pip install -i https://pypi.cloud.soda.io soda-postgres - In a code editor, create a new file called
configuration.yml, then copy paste the following config details into the file. Provide your own values for the fields, using your own API key and secret values you created in Soda Cloud. Replace the value ofmy_database_namewith the name of your PostgreSQL data source.data_source my_database_name: type: postgres host: port: username: password: database: schema: soda_cloud: # For US region, use cloud.us.soda.io # For EU region, use cloud.soda.io host: cloud.soda.io api_key_id: api_key_secret: - Save the file. From the command-line, in the same directory in which you created the
configuration.ymlrun the following command to test Soda’s connection to your data source. Replace the value ofmy_datasourcewith the name of your own PostgreSQL data source.soda test-connection -d my_datasource -c configuration.yml - To create some basic checks for data quality, run the following command to launch Check Suggestions which auto-generates checks using the Soda Checks Language (SodaCL), a domain-specific language for data quality testing.
- Identify one dataset in your data source to use as the value for the
-dsoption in the command below. - Replace the value of
my_datasourcewith the name of your own PostgreSQL data source. - Answer the prompts in the command-line and, at the end, select
yto run a scan using the suggested checks.soda suggest -d my_datasource -c configuration.yml -ds your_dataset_name
- Identify one dataset in your data source to use as the value for the
- In a browser, log in to your Soda Cloud account, then navigate to the Checks dashboard. Here, you can review the results of the checks that Soda executed in the first scan for data quality. After a scan, each check results in one of three default states:
- pass: the values in the dataset match or fall within the thresholds you specified
- fail: the values in the dataset do not match or fall within the thresholds you specified
- error: the syntax of the check is invalid, or there are runtime or credential errors
- Based on the check results from the first scan, address any data quality issues that Soda surfaced so that your data migration project begins with good-quality data. Refer to Runs a scan and review results for much more detail.
- If you wish, open the
checks.ymlthat the check suggestions command saved locally for you and add more checks for data quality, then use the following command to run the scan again. Refer to SodaCL reference for exhaustive details on all types of checks.soda scan -d my_datasource -c configuration.yml checks.yml
Migrate data in staging
- Having tested data quality on the PostgreSQL data source, best practice dictates that you back up the existing data in the PostgreSQL data source, then replicate both the PostgreSQL and an empty Snowflake data source in a staging environment.
- As in the example that follows, add two more configurations to your
configuration.ymlfor:- the PostgreSQL staging data source
- the Snowflake staging data source
data_source fulfillment_apac_prod: type: postgres host: 127.0.0.1 port: '5432' username: ${POSTGRES_USER} password: ${POSTGRES_PASSWORD} database: postgres schema: public data_source fulfillment_apac_staging: type: postgres host: localhost port: '5432' username: ${POSTGRES_USER} password: ${POSTGRES_PASSWORD} database: postgres schema: public data_source fulfillment_apac1_staging: type: snowflake username: ${SNOWFLAKE_USER} password: ${SNOWFLAKE_USER} account: my_account database: snowflake_database warehouse: snowflake_warehouse connection_timeout: 240 role: PUBLIC client_session_keep_alive: true authenticator: externalbrowser session_parameters: QUERY_TAG: soda-queries QUOTED_IDENTIFIERS_IGNORE_CASE: false schema: public
- Run the following commands to test the connection to each new data source in the staging environment.
soda test-connection -d fulfillment_apac_staging -c configuration.yml soda test-connection -d fulfillment_apac1_staging -c configuration.yml - Using an orchestrator such as Airflow, migrate your data in the staging environment from PostgreSQL to Snowflake, making any necessary transformations to your data to populate the new data source. Reference Migrating data using Airflow for an Airflow setup example.
Reconcile data and migrate in production
- With both source and target data sources, you can use SodaCL reconciliation checks to compare the data in the target to the source to ensure that it is expected and free of data quality issues.
Begin by using a code editor to prepare arecon.ymlfile in the same directory as you installed Soda, as per the following example which identifies the source and target datasets to compare, and defines basic checks to compare schemas and row counts.reconciliation OrdersAPAC: label: "Recon APAC orders" datasets: source: dataset: orders_apac datasource: fulfillment_apac_staging target: dataset: orders_apac datasource: fulfillment_apac1_staging checks: - schema - row_count diff = 0 - Referencing the checks that checks suggestions created, add corresponding metric reconciliation checks to the file to surface any delta between the metrics Soda measures for the source and the measurements it collects for the target. Refer to the list of metrics and checks that are available as reconciliation checks.
Examples ofchecks.ymlandrecon.ymlfiles follow.# checks.yml prepared by check suggestions filter dim_product [daily]: where: start_date > TIMESTAMP'${NOW}' - interval '1d' checks for dim_product [daily]: - schema: name: Any schema changes fail: when schema changes: - column delete - column add - column index change - column type change - row_count > 0 - anomaly detection for row_count - freshness(start_date) < 398d - missing_count(weight_unit_measure_code) = 0 - missing_count(color) = 0 - duplicate_count(safety_stock_level) = 0# recon.yml reconciliation OrdersAPAC: label: "Recon datasets" ... checks: - schema - row_count diff = 0 - freshness(start_date) diff = 0 - missing_count(weight_unit_measure_code) diff = 0 - missing_count(color) diff = 0 - duplicate_count(safety_stock_level): fail: when diff > 10 warn: when diff between 5 and 9 - Run a scan to execute the checks in the
recon.ymlfile. When you run a scan against either the source or target data source, theScan summaryin the output indicates the check value, which is the calculated delta between measurements, the measurement value of each metric or check for both the source and target datasets, along with the diff value and percentage, and the absolute value and percentage. Review the results Soda Library produces in the command-line and/or in the Checks dashboard in Soda Cloud.soda scan -d fulfillment_apac_staging -c configuration.yml recon.yml - Based on the scan results, make adjustments to the transformations in your orchestrated flow and repeat the scans, adding more metric reconciliation checks needed.
- Compare more source and target datasets by adding more reconciliation blocks to the
recon.ymlfile. Tip: You can run check suggestions against new datasets and use those checks as a baseline for writing metric reconciliation checks for other datasets in your data source.reconciliation OrdersAPAC: label: "Recon APAC orders" datasets: source: dataset: orders_apac datasource: fulfillment_apac_staging target: dataset: orders_apac datasource: fulfillment_apac1_staging checks: - schema - row_count diff = 0 reconciliation DiscountAPAC: label: "Recon APAC discount" datasets: source: dataset: discount_apac datasource: fulfillment_apac_staging target: dataset: discount_apac datasource: fulfillment_apac1_staging checks: - schema - row_count diff = 0 - After reconciling metrics between multiple datasets, consider writing more granular record reconciliation checks for the most critical data, as in the example below. As these checks execute a row-by-row comparison of data in a dataset, they are resource-heavy relative to metric and schema reconciliation checks. However, for the datasets that matter most, the resource usage is warranted to ensure that the data you migrate remains intact and as expected in the target data source.
reconciliation CommissionAPAC: label: "Recon APAC commission" datasets: source: dataset: commission_apac datasource: fulfillment_apac_staging target: dataset: commission_apac datasource: fulfillment_apac1_staging checks: - rows diff = 0 - After reviewing multiple scan results and correcting any reconciliation issues between source and target datasets, you can execute the migration in production.
After the migration, use the samerecon.ymlfile to run a scan on the migrated data in production to confirm that the data in the target is as expected. Adjust thesoda scancommand to run against your production data source instead of the staging data source.soda scan -d fulfillment_apac1_prod -c configuration.yml recon.yml - (Optional) If you intend to execute the migration of data between data sources frequently, you may wish to invoke Soda scan with the reconciliation checks programmatically within your pipeline orchestration, such as in your Airflow DAG. To access an example of how to include Soda scans in your DAG, see Test data in production.
Go further
- Need help? Join the Soda community on Slack.
- Learn more about reconciliation checks in general.
- Write reconciliation checks that produce failed row samples in Soda Cloud to help you investigate the root cause of data quality issues.
Was this documentation helpful?
What could we do to improve this page?
- Suggest a docs change in GitHub.
- Share feedback in the Soda community on Slack.
Documentation always applies to the latest version of Soda products
Last modified on 08-Aug-24